Many Faces of CQRS

At its core, CQRS — Command Query Responsibility Segregation, has a simple goal — to treat reads and writes as separate models. This simple idea can take many shapes depending on both the context where it is used as well as the choice of implementation used. This post attempts to analyze the various shapes of CQRS and how all of those support the central idea of de-coupling reads and writes.
To recap. In the beginning there was a big application that used a big database, and all the data was there to be read, updated, and deleted from this database. Applications used transactions and various locking mechanisms to manage the consistency and isolation of data in this database. Things got a little sophisticated with use of ORMs but beneath the scenes, it was basically the same concept. The model of an entity and data in general for queries, updates etc. was the same. It followed the same structure in database tables, views and in application “beans” and DTOs. In simple domains, there is enough commonality between read and write models, so a common model for both is simpler and easier.
Then world around got complicated. The volume and the kind of data produced has changed. It is not just simple CRUD style applications anymore. There is no canonical data model for all kind of operations. Cloud, Microservices, Streaming, Reactive systems meant that there was now a need to think about data origination and data consumption in this diverse, distributed & always-in-motion differently. CQRS is one of the consequences of such a thought process. It is this idea to look at data differently for recording and reading purposes and to acknowledge that those two models do not need to be same. Once that is accepted, it opens a whole lot of options and choices to reason about the two models with choices of:
· Data Models
· Datastore
· Consistency Options
· Application Design
· Runtime Environments
· Access Patterns (e.g., Heavy Reads, Few Writes)
Note that before term CQRS was coined, Reporting Database via Datawarehouse and Analytics products were still being used, which in a way, followed the core theme of CQRS, to decouple reads and queries. These products usually sourced data from the databases using some kind of ETL or database replication processes and were purposed as information systems. While these technically adhere to CQRS at a level, this term now commonly refers to a single process (e.g., a module or a microservice) employing read and write models for different types of user requests. So, it is more of a OLTP pattern instead of being an erstwhile OLAP pattern. Indeed, having analytics systems and data lakes etc. can be a causal benefit of CQRS, but those are not a fundamental reason.
One last point worth mentioning is that CQRS has gained popularity after Domain Driven Design became much talked about. The Command & Query refer to domain events in DDD, so instead of being a simple WriteReadResponsibilitySeggretaion, it has come to be known with the DDD version of those terms.
The next section tries to analyze the different options available for implementing CQRS and how these options affect the traits of: Data Model, Consistency, Database Choice, Transfer Model. There is no significance to the ordering of these options but maybe they go from simple to relatively complicated.
- App Centric CQRS

DB Model : Same
Object Model : Different
Consistency : Strong *
Database Instances : Same
Database Types : Same
Transfer Type : NA
Transfer Model : NA
In a simple form to implement the theme of CQRS, applications are designed to create different read and write services & models to provide a clear module sub-boundary between these operations. The command service executes the writes in a database. The query service reads from the same database but produces a different query model that is purposed, for example for display in UI. Query model can make choice of transformation and projection of this data.
The underlying database remains the same, so the DB constrains & schema are still in force in both.
Since the underlying database is the same, DB consistency is strong (*).
As an example, the ORM frameworks, among other things create an “Object-Mapping” that lets a developer treat objects as entities and often has all the “entity-operations” abstracted out in the same entity class. While this has been working well in simple cases, it does not provide a design for different read and write models and services and two are treated as implementations of CRUD operations in the same entity class.
*Also depends on the Isolation settings of the DB. Consistency here is mapped to the Isolation in ACID properties (not the C in ACID)
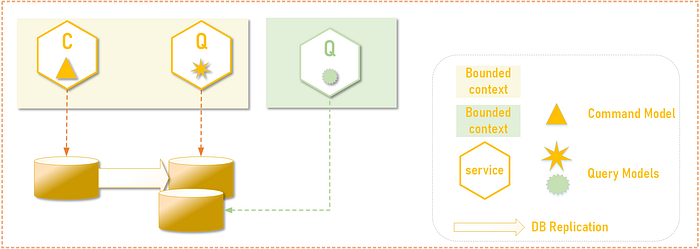
2. DB Read Replicas
DB Model : Same
Object Model : Different
Consistency : Eventual | Strong
Database Instances : Different
Database Types : Same
Transfer Type : Asynchronous | Synchronous
Transfer Model : DB Replication
Read Replicas provide different read database that contains a read only copy of the main write database.
The services can use different querying model in the code since the database structure is exactly same as write database.
This pattern is used to offload the write database from queries to balance the query traffic across one or more read instances.
Replication tools are usually provided by the DB vendors like IBM DB2, Oracle. Newer cloud-native, managed databases provided read replicas as managed service and takes care of replication and high availability of the read replicas.
In specialized cases the DB replication can also be tuned for strong consistency (aka a replication-factor). In which case the replication is done to favor strong consistency model (the C in the CAP). For example, AWS S3 provides strong read-after-write consistency model. Cassandra provides configurable read consistency levels settings.
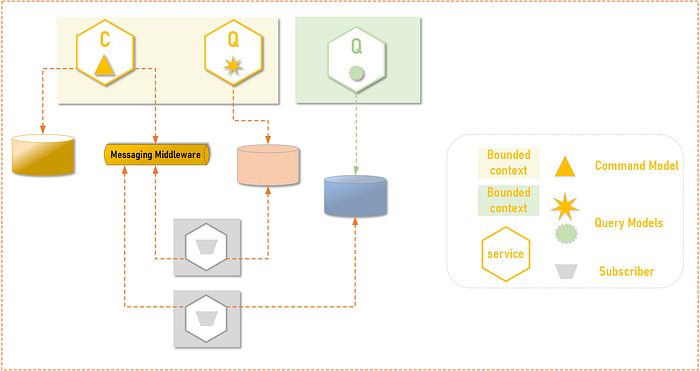
3. Event Publish
DB Model : Different
Object Model : Different
Consistency : Eventual
Database Instances : Different
Database Types : Potentially Different
Transfer Type : Asynchronous
Transfer Model : Eventing
Many event-driven patterns compliment CQRS style applications. The command services write to a command database. So, any domain event that changes the state of the domain is a command and is written to a database optimized for writes. Command database may also be read for a read-before-write case transactionally, but that is usually within a small context of an aggregate. In addition, the command service also publishes the command into a messaging system and a command event with canonical event structure.
This event can be subscribed by any service and in this case, a query service subscription listens to the event and builds a local database that is optimized for reads. As opposite to DB replication, this approach provides the freedom to project the event in any read-optimized way. Indeed, event the choice of underlying database can be different from the command database, thus enabling a polyglot persistent.
Important points:
1. The query side would see an eventually consistent data and thus needs to account for this in the application design and user experience. The query DB should not be read for data to be used for writes in command DB.
2. The command service needs to somehow manage DB write and event publish transactionally (both ok OR both rolled back). This may mean XA or 2PC approach which may be fragile.
3. In case of failures the event may be delivered with multiple retries and thus can reach the subscriber multiple times (referred to as “At-Least-Once” delivery). The subscriber needs to be idempotent and process an event only once. The messaging system is augmented with a DR component such as Persistent Queues or Dead Letter Queues to preserve messages in case of subscriber or messaging system failures.
4. Events published as per command service’s execution time, so there are no ordering guarantees. Which means a domain event D1 occurred at T1 can reach a subscriber later than another domain event D2 emitted at T2. In addition in case of subscriber failures, the events may be re-delivered out-of-order, when subscriber is healthy again. Out-Of-Order delivery has to be addressed (especially in In JMS and AMQP style messaging, where-as in event streaming systems like Kafka or Akka & Kinesis Streams, the consumer is in control of the message offset that they are consuming for a partition). Typically, this is addressed by maintaining event timestamp as a message attribute which is different than the timestamp header created by the messaging middleware when the event is published to it.
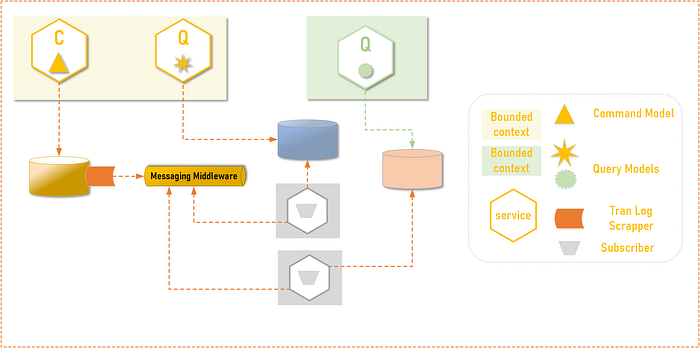
4. CDC (Change Data Capture)
DB Model : Different
Object Model : Different
Consistency : Eventual
Database Instances : Different
Database Types : Potentially Different
Transfer Type : Asynchronous
Transfer Model : Log Tailing, Eventing
Similar to the event publish in the benefits and traits. CDC make the command database as the source of the command event. The command service just needs to transactionally commit to the transaction database and then the database transaction log becomes the event trigger, absolving the command service to manage DB writes and eventing transactionally.
Additional log scrapper component is introduced here, that is a usually a database native component and is “hooked” to an event store to publish temporal ordered event.
Important points:
1. Ref Event Publish #1
2. Ref Event Publish #3. In addition, since command database transaction log has all the changes still, it provides another layer for retries in case of failures.
3. The message ordering is guaranteed since the database transaction log is ordered.
Database vendors provide a log scrapping system for popular databases. These are combined with the CDC tools to enable source and destination connectors. Two popular choices are Debezium and Kafka Connect. Kafka Connect provides support for large number of “source” and “sink” connectors.
Cloud databases provide this pattern as a managed cloud-native service. For example AWS Dynamo Streams ( Supported by AWS Kinesis Data Stream).
This pattern is also captured in the microservices Transaction Outbox pattern & Transaction Log Tailing pattern.
Frameworks like Axon & Eventuate provide support for this pattern.
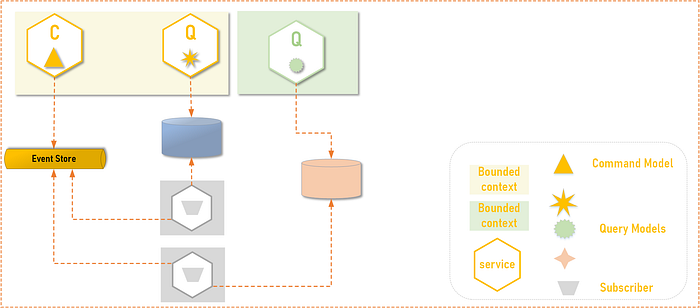
5. Event-Sourcing & CQRS
DB Model : Different
Object Models : Different
Consistency : Eventual
Database Instances : Different
Database Types : Potentially Different
Transfer Type : Asynchronous
Transfer Model : Eventing
Event Sourcing is an approach to design the applications as a series of domain events that are stored in a temporal order in an event store. The event store could be a event platform such as Kafka or AWS Kinesis and can also simply be a database. Event Store is the “single source of truth” about the state. The important point though is that there is no “current-state” of domain. The current state is a derived state which can be achieved by replaying the events on an aggregate. Event sourcing provides a implicit audit log of changes as a set of domain events. On the other side, since there is no entity state, it is not possible to query for an entity in the command event store. To overcome this, CQRS is often sees as a complimentary pattern to event sourcing, to make the derived state of entity available in a separate query data store.
It is possible to implement CQRS using the CDC pattern as well. In case the event store is a messaging system like Kafka, the event store becomes a subscription for the query service (and indeed any other service like analytics, fraud prevention etc.) to get a stream of domain command events and create a read optimized model for querying.
What if command service needs to read some entity data? Ideally it should not depend on a previous state since all command service should do is an append-only log of commands (the choice of event store i.e. messaging vs DB is of less significance for this point). But what if? Can the command service also read the query store projection? The answer is contextual and may be it can, but there is an eventual consistency at play here. As long as as command processing does not depend of strong consistency guarantees of data it needs to read, it should fine to read. Probably keeping this as an edge case is prudent.
Frameworks provides all plumbing components for implementing event-sourcing and CQRS. Lightbend Akka & Axon are two examples.
Few Aspects :
Caching: Caching at read layer is a generic choice that is available in all the options and not necessary a consequence of CQRS.
Consistency: Data consistency considerations are paramount here. The read-only data, command side reads and read-before-write data cases need different consistency guarantees.
